I showed up at the location of Cars & Coffee Aliso Viejo at 6:45am and there were already about 20 cars there. It was very cold for California standards, but it did not stop the car enthusiasts. The place was already full by 7:30am.
Here the link to my album with the pictures that I took with my iPhone:
Let's start with a few options: (A) Be fast, risk failure and if needed quickly recover to succeed. (B) Be slow and successfully launch. Obviously the option A does NOT apply to companies that are building planes, ships, cars, medical equipment and what not. However, it does apply to a lot of other IT organizations.
In option A, I am NOT talking about recklessly failing. I am talking about leading a team and trusting them without watching every single line of code and without introducing too many gates during the development of a project. As long as you have professionals on your team, you really need to use "let the baby out of the crib" methodology and allow them to fall as they are learning to walk as a team.
When I say "fail", I also don't mean failing foolishly breaking every rule in the architecture book; that's being foolish and not fast. I am talking about the culture where risking normal failures is NOT looked down upon. It is all about keeping the levels of this risk within normal boundaries and that requires a skill.
This is what "Be Agile" could mean. Let's call it "The Function of Agility":
We don't need books and certifications. It just boils down to the above Function of Being Agile that we need to stick to; everything else is catering "Be Agile" approach to your company and it may mean that you implement what Scrum organizations put in place, or it may mean that you deviate from it in order to best achieve the goals in your work environment.
How do you gauge if you are on the right path?
It is simple. If the number of your failures is increasing over time and it is actually slowing you down, than you have to revisit the whole approach.
If the number of your failures is the same or less and you are not slowing down your development and deployments, then you are on the right path as long as those failures are not critical to the business. The goal is to keep iterating and NOT repeat the failures.
At the end of the day, if you have the culture that does NOT look down upon slight failures, your team will have so much fun which typically leads to amazing results. It is beautiful to watch the work in action. You can't really measure every step of the way, but what you can measure is how much more value you provided to your customers. That's the measure that matters at the end.
I just recently attended a very good two-day training session on AWS. Jon Gallagher (our instructor) is very knowledgeable and good in painting the full picture on AWS. His labs were great too.
Here is the summary of the material covered in this training. We covered a lot in two days.
Number 1 thing I tell fellow developers on my projects is:
Pretend that after you check in your code (even though it is isolated in your project branch) that I will take your code and put it in production right away.
Then ask yourself if that code will break existing behaviour of your existing sites/applications. If the answer is "Yes", then you should not have checked in that code in the form it was in.
Addressing all the issues as you are coding instead of dealing with them during merging your branch back into main trunk is the right thing to do.
Basically the question is: Pay me now or pay me later?
I'd rather pay with the right mindset before you even write a line code. Obviously the mindset is not good enough; you need unit-testing and integration testing to make sure it truly does not break existing functionality . Some of us have been calling this "stubbing out your code" and more recent buzz word would be "feature toggle".
What are some typical examples?
Let's take the most simple example. You are writing a brand new method that nobody is going to use yet and you want to check in your code because it is in good shape. Basically this code is stubbed out by default; you can't break any existing functionality.
Let's consider another example. Let's say you are asked to introduce a new feature called "RankCustomer" on ONLY one of your sites called Site A. You implemented all the functionality and you also prepared the code that invokes this RankCustomer module in your order processing methods that are shared by multiple sites. Let's say you check in the code in this shape. What would happen? If I pushed this code to Production environment, all the sites would attempt to call RankCustomer module and it would break right away and cause a Severity 1 issue. Let's say RankCustomer module needed some certificates/keys installed and if I push the code without the certificates/key installed, it would break production. So how would you check in this code properly? You would introduce a flag in your code for this feature. If this flag is NULL (not existent in config file) or explicitly set to FALSE, the RankCustomer module would never be called. This means that if you literally take that compiled code to production WITHOUT even pushing any config files or installing any certificates, it will never be invoked in production. That's how stubbing out works.
This mindset is something that needs to be preached during any project; that's how issues are prevented and over time this just becomes natural when you work with your teammates longer. You just take care of each other.
You may ask what the drivers of traditional manual-transmission cars and C/C++ programmers have anything to do with each other.
Well, I am a software engineer and I am also a car enthusiast (aka a petrolhead in UK). I am noticing certain trends in both the car industry and the software engineering community/industry; therefore, I wanted to share my opinions.
I started programming in Basic before I even owned my own computer. I remember when I first learned a for-loop in Basic, I walked over to my friend’s house and typed it up on his Commodore 64. When I was in high-school, I did more Basic (Better Basic and QuickBASIC) and also some Turing (not Turing Machine….I am talking about a language invented by University of Toronto to teach programming and it was Pascal-like). Then I switched to C/C++ and learned all about proper handling of memory and what we call “unmanaged” code these days. C/C++ were the choice if you wanted to do some low-level programming or also if you wanted to write scalable applications. Then some other programming languages started becoming more popular and these were the languages that promised developers the capability of scalable programs without worrying about the complexity that you had to deal with while programming C/C++. Java is one of those languages. Then Python, Ruby and C# (.NET) also joined Java in this group. We also have Node.js, Golang and Scala as more recent players that have proven “simplicity” and scalability.
You may say: “I like to code in C/C++ because it gives me a special satisfaction”, but as a software engineer, you have to be true to yourself and you really need to ask what the right tool is for that given job. C/C++ are the right choice if you are building something where performance is absolutely crucial or you are building some drivers where you really need C/C++. However, if you are building a simple website that is collecting customer’s input and saving it to database, then you really do not want to use C/C++. In these situations, developers are choosing C#, Java, Ruby, Node.js, and Python because they are relatively fast and much easier to maintain and expand.
What I am trying to say is that fewer and fewer programmers are using C/C++ and it will be harder to find developers in this area from year to year. C/C++ will not go away, but no high-school students would be exposed to it. Maybe even no university students would be exposed to it.
I will switch over to cars and explain how driving traditional manual-transmission cars is related to C/C++ programming.
Until automatic transmissions were invented, manual transmission was the only choice. People who liked to drive learned to drive and they enjoyed driving manual-transmission cars. A lot of people opted out of driving because it was just complex for them. Then manufacturers started putting automatic transmissions in their cars. Customers started buying cars with automatic transmission because they were more convenient (easier to drive), but these automatic transmissions were not yet efficient enough from performance nor economical point of view.
In last 10 years automatic transmissions (traditional automatics and dual-clutch automatics) started being engineered to equal and exceed the performance and economical levels of manual transmissions. Nowadays, you can buy cars with automatic transmission that will give you better MPGs and better 0–60 times than the exact cars with manual transmission. In fact, a lot of cars are stopped being manufactured with manual transmission because there is no market for them. One of these cars in the latest 991 model of Porsche 911 GT3; Porsche is only selling the model with dual-clutch automatic transmission also known as PDK; some people refer to these transmissions as “automated manuals”. This is frustrating Porsche car enthusiasts and specifically those purists. However, I understand why Porsche is doing this; they believe that manual transmission is the weakest link in the design of this car and to take this car to next level, they decided to design and manufacture 911 GT3 with dual-clutch transmission only.
As a car enthusiast I like to drive cars and with manual transmissions because there is a X-factor about them that make my driving experience more enjoyable, but at the same time I fully recognize that automatics can perform better and that needs to be well recognized; that’s why a lot of racing leagues use cars with dual-clutch sequential transmissions.
Cars with manual transmissions will not be fully extinct, but over next 10–20 years, they will be harder to find the same it will be harder to find skilled C/C++ programmers.
I have been watching Big Bang Theory from day one. Every time there is a car scene, I notice that they are using cars with low headrests or they fully remove the headrests. It looks very obvious.
I understand if you have a scene with passengers in the back and you don't have a good angle, but why do they need to remove the headrests if they have a scene with only two people in the car?
How do you prototype something quickly, keep it simple and at the same time have it ready to be expanded into a real product?
During my last two-week vacation I spent a bit of time to learn Node.js. My goal was to learn it enough so that I can put together a little template for me in order to easily develop some prototypes with a bit of Web API via Node.js and HTML/Javascript on the client side.
I am glad that I spent time learning a bit of Node.js because when I came back from my vacation, I needed to develop a prototype for my team as part of our first sprint of a big project. I just spent last week some time to develop a prototype and I am ready to share it with my team members on Monday.
The next thing for me in my personal time is to learn Node.js more so that I can apply it at the enterprise level when needed. All the error handling and robustness that comes naturally in C#, I need to develop that skill in Node.js.
I already posted a bunch of pictures on Google+ during the Monterey Car Week, but I will use this opportunity to share the full album with you.
It was a great week. Compared to last year, it seemed that the level of enthusiasm this year was much higher. For me the most fun part was watching the delivery trucks unload these amazing cars. The atmosphere around the town was also great. Some locals may not like this busy week, but overall it is a great thing for Monterey.
With the trend of front-end Javascript frameworks, there is more and more logic pushed to the client side in the Javascript code. With all this comes more responsibility when we talk about security. It requires a lot of discipline. Front-end and back-end (API) developers need to work very closely together so that secure information is not revealed in the Javascript code.
I've tried at least a dozen of well-respected task management apps and none of them give me a complete solution. Then I realized that a solution is in front of me every day. Don't look further than Gmail as your task management tool on your smartphone or desktop browser. Gmail app on iPhone is not like the regular email app that only keeps your emails for X number of weeks. All the emails are there and the searching is so easy. Labels/Folders are easy to use and it is easy move things around or apply different labels.
Don't get me wrong. I like my OneNote for all the work related items, but for simple tracking of my to-do personal items, I have been using Gmail app on my iPhone and Gmail in the web browser.
For example, I created two labels: - TODO_Current - TODO_Backlog
Before the beginning of the week, I review my backlog and put it under Current if I plan to work on it that week.
Then throughout the week, I review the Current list and I work on the items.
For regular bills I set up reoccurring meetings in Google Calendar and I set up reminders to get emails when I have to pay bills. Those would go under my Current list for the week.
The two features that I really like are:
How conversations (email threads) work encourages you to easily use that the email thread and keep replying to yourself on tasks that take longer. Then you can just scroll through the email thread and see what you have done so far and continue working on it.
Copy and paste from other websites into Gmail keeps the HTML format perfectly. This is crucial when I read computer/coding article and I want to revisit it, I typically save the URL and also copy and paste contents of that page into Gmail for easy reference.
With this system, I feel so organized.
Yes, there are very good tools that I tried that do this much better on the mobile device, but I could not find one that does it great on both desktop and mobile. For example, I love OmniFocus app for iPhone, but I don't have anything for my PC at home or at work. I paid premium to to play around their iPhone app, but I decided that Gmail is the best all-around solution for me.
Manifesto and the role of tools within the world of Agile Software Development?
Part 1 of the manifesto: “Individuals and interactions over processes and tools”
Are the tools we use to support our Agile Software Development ruining the actual agility on day-to-day basis? Are these tools affecting the chemistry of the team?
Are the companies that sell these tools feeling the pressure to innovate and to keep owners and stockholders happy? Then the innovation turns out to be tipping the manifesto statements to the right side (contradicting the manifesto) because the decision makers in companies who buy these tools want the tools that are all about tracking, measurements, and reporting.
I am putting a lot of questions in this post and I am not going to necessarily give you answers to these questions. This post is more about having you think about these things and realizing whether you as a software developer are already impacted by these tools or specific features of these tools. Are you asked to use certain features of these tools and you think that these features cross the line and tip the weight to the right side of the manifesto which really means contradict the manifesto itself?
Over the years I used many different tools that supported waterfall and agile development. Some of the more recent tools for agile development have been:
Rally
PivotalTracker
Trello
Jira (some exposure)
Asana (not necessirily build for agile but for overall task management)
OneNote (yes, I said OneNote)
I am not going to praise or criticize specifically any of these tools. Some of them are simple and get the job done without forcing you to do it certain way. Some of them are more complex because they have all kinds of features for measuring and reporting and this generally looks attractive to managers who see this as an opportunity to closely track the work that the team is performing.
The question becomes, who is supposed to pick the tool? Are the members of the development team supposed to recommend a tool that helps them get the job done the best way, or is the management team supposed pick the tool that works better for them?
What did we do before the age of tools? Yes, we used Post-it notes !
A simple board with Post-it notes divided in a few columns did the job for a team in one location. It was a very simple approach. The tools should also keep things simple. They should just take it one step further without negatively impacting the progress, the creativity and agility of the team. On the other hand, if you go one step too far with the tools, the team will know if their agility is impacted and if the fun-factor is gone. We all know that if you take the fun-factor and agility out of the team, then the team members are not operating on their own terms any more; the authenticity slowly goes away.
This is about your household computers and which type of computer is used 90–95% of the time. I am a software engineer and I still need to use a Windows laptop if I want to do some development at home after a long day at work.
As for most used household computers, we switched from Windows to ChromeOS when the original Chromebook Samsung 11" came out in 2011. Then we switched to HP Chromebook 14" and that made the experience even more consistent and enjoyable.
All this time we were using LastPass for password management. I like how LastPass approaches their security but recent hacks scared me a bit and I started thinking about one basket with all the eggs in it and all of this being in the cloud with LastPass (no offense LastPass). Then I decided that my wife and I should switch to a total opposite approach for password management and use 1Password desktop software without keeping any password management data in the cloud. That resulted in getting a Macbook Air 13" as I wanted a full OS with less maintenance. We have been enjoying the Macbook Air, but I am still appreciating the consistency of any Chromebook and 100% productivity. Mac OS is very consistent and it just works but when I compare it directly to ChromeOS, it still has some unexpected performance behaviors which are not worth mentioning if I compare it to Windows.
If ChromeOS had a built-in way of zipping and unzipping AES 256bit files or something built-in along a lighter version of TrueCrypt, then I would use ChromeOS again anytime. Maybe LastPass and Google can work together to produce a truly native LastPass app for ChromeOS. That would allow me to occasionally take that encrypted file from one Chromebook to another and still have access to my password management information. As for everything else, I have nothing to hide and I embrace the cloud as much as possible.
I am excited to see where ChromeOS team at Google will take ChromeOS over next few years.
Let me know if you are facing similar dilemmas with your household computers and if you have any recommendations for me on ChromeOS could solve my problems at this time.
Estimating project is not easy if you don’t have a right approach. You can be in MS Project land trying to figure out little details, but those details change and then you are stuck maintaining schedules in MS Project.
A lot of companies are trying to change to use “Agile” methodology and I am putting the word Agile in quotes because there is no company out there that is following exactly what you are taught in ScrumMaster courses and SAFe courses. That means that companies sooner or later end up doing what works for them and that could be an approach that belongs somewhere on the line between Waterfall and Agile; for some companies closer to Agile and for companies closer to Waterfall.
For example a lot of companies get a list of projects that need to be estimated, prioritized and approved by a board before projects can be worked on. Then when they are approved, you are asked to provide project schedules with milestones and deadlines with very high-level requirements. Then some of these organizations say “let’s run these projects using agile methodologies”. What does that really mean?
What does that really mean if you have already broken down the project into a list of tasks and you estimated it all?
Can the agile team take these requirements and start assigning points to user stories and deciding how much to handle in a given week? In the meantime based on estimates, you already know how much needs to be handled in order to even have a chance to deliver the project?
Is that really fooling the members of the team believing that they will set the velocity based on how much the team can handle and in the meantime the estimates have been already committed?
Let me explain how I approach this. Let me first step back to the point when the estimates are being provided. What works for for me is reading the requirements document and breaking down the project into a list of features and sub-features. Then if the requirements document is written in such a way that it lists the user stories, you can easily distribute these user stories into the appropriate sub-features. If the requirements document does not explicitly list the user stories, then I would put a product owner hat on and extrapolate the user stories out of the requirements document.
Now that I have all the user stories under each sub-feature, I can do some high-level estimating on each story and the unit for estimation is the number of days. It is not some virtual story points and it is not hours; it is the number of day and you will see why later in this article.
After estimating each user story under each sub-feature, you can add up the estimates and have the list of sub-features and numbers for each sub-feature.
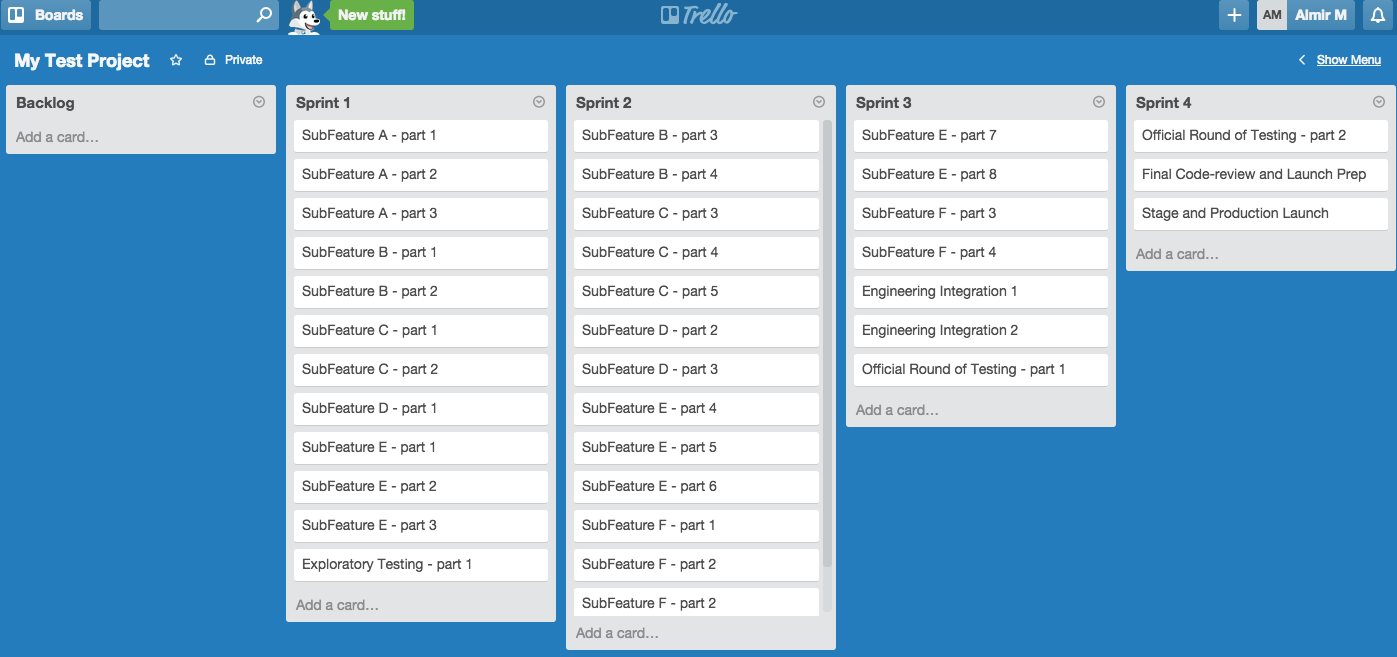
Now that you have the list of sub-features and estimate for each sub-feature, it is all fun after this point. It is fun because I like using Trello website to pre-plan all the sprints and ultimately produce the deadline (production launch date), because that’s what business expects from us. NOTE: I don’t do sprint planning at the user story level; I do this exercise of sprint pre-planning at the sub-feature level in order to produce that deadline and to have a rough idea how each sub-feature needs to be worked on throughout the project.
What are the steps to be taken before playing the drag-and-drop game in Trello?
Decide on the duration of the sprint (let’s say 4 weeks)
Take the list of sub-features and estimates and break down each sub-feature into multiple sub-feature parts that are each 5 days worth of work. For example, if you have a sub-feature that has the estimate of 20 days, then you would break that sub-feature into Sub-Feature A part 1, Sub-Feature A part 2, Sub-Feature A part 3, and Sub-Feature part 4.
Now you are ready plug this all into Trello backlog list and then the game of dragging and dropping starts :)
Here is how it could look like in the backlog list when you start:
Now that you have all the sub-feature parts in the backlog, it is time to gauge what the optimal number of resources is. Let’s do some simple math.
6 resources
4 week sprints (20 working days)
if everybody is a robot, then the team should be able to chunk away 120 days (6x20) out of the estimates. Yeah right !!! With all the meetings and interactions between teammates, a reasonable number to achieve in each sprint would be 60–80 days worth of work. If each part of the given sub-feature is equivalent to 5 days worth of work from the estimates, then you should be able to drag and drop 10+ of those parts into a given user sprint.
You as the technical lead and technical project manager know best how each sub-feature is related to each other and you are deciding those things as you are loading each sprint with the list of sub-feature parts.
Here is how it may look after going through this exercise. It looks like the duration of the project would be around 14 weeks (3.5 months). If you know what the start date is, then you can easily calculate the production launch date. You also know when you need to start each sub-feature and when each sub-feature is supposed to be completed. That can help you point out some major milestones to your senior management team.
You are done. Provide your boss the duration of the project, major milestones and the production launch date that you can achieve based on these high-level estimates.
What’s next?
Well, now you need to share this with the team and help out the team do proper sprint planning at the user story level by using this sub-feature plan. I happened to use Trello just for the purposes of “sub-feature” planning, but when it comes to sprint planning at the user-story level, your team will need to use whatever tool your company approved.
When you develop your applications, do you put thought into a proper logging mechanism? In a perfect world, there should be no errors in the logs, but we all know that’s not the case in reality. Then how do you know that the project you just launched to a production environment is not introducing new errors or new types of errors on top of already existing errors that your triage team has been investigating?
Maybe on day 1 of your launch, you don’t see customer complaints, but in reality your systems are hurting or bleeding slowly. Yes, a network operations team could be checking the high-level health of the systems through a list of dashboards, but what are we software developers going to do to introduce a new level of detection? This all starts from the enterprise architecture and frameworks you build. Let’s assume you have a very robust logging mechanism and that this mechanism allows you to log the happy path. Let’s also assume that you have very clean guidelines for error and exception handling and utilizing the logging framework where necessary.
Now that you have all of the above in place, at the beginning of your project that is implementing business requirements within the existing framework, you have ability to cleanly define the top 20 cases to measure the success of the new code/features. Each developer can use this top-20 list as a guideline while developing the code and logging happy/negative cases. Let’s say your code is now in production and you are scanning through the logs manually and detecting the top-20 cases. Is this efficient? Are you supposed to do this on daily basis manually?
My recommendation is that you develop a lightweight solution that will be able to automatically do the following for you:
* Scan the logs on daily/hourly basis and produce the count of the top-20 scenarios and display the results in a table on some internal dashboard website
* Have ability to detect if the number of errors in each category increases by more than X% (daily comparison of errors per Y units of work and units of work could be somehow defined and tied to the traffic on your website).
* Have ability to detect if new types of errors and exceptions that start happening so that the team can manually assess the situation and then add each new type of error to the top-20 list and start tracking it on daily basis.
If you have all of this automated, then there is no manual work needed when you launch something to production. You will be able to tell if your new code is hurting the numbers on existing top-20 categories and you will also be able to tell if you started introducing new types of errors that hurt the revenue of your company. Let’s assume that your production deployment involves deploying to a smaller/secondary data center first and then later to the rest of your data centers. Then this type of mechanisms can help you decide whether you continue deploying to the rest of data centers after deploying to that smaller data center.
These are all simple concepts. You can spend minimal efforts in building it yourself or maybe decide to buy a solution. The importang thing is to always take the “keep it simple” approach in decision making.
Conclusion:
Start by tracking top-20 errors on daily/hourly basis and use the percent of change as the gauge for the success of your code being pushed to production environments. Detect the newly introduced low-level engineering errors in production on time to gauge the success of your launch. Don’t over-design this! Keep it simple!