
A lot of companies are trying to change to use “Agile” methodology and I am putting the word Agile in quotes because there is no company out there that is following exactly what you are taught in ScrumMaster courses and SAFe courses. That means that companies sooner or later end up doing what works for them and that could be an approach that belongs somewhere on the line between Waterfall and Agile; for some companies closer to Agile and for companies closer to Waterfall.
For example a lot of companies get a list of projects that need to be estimated, prioritized and approved by a board before projects can be worked on. Then when they are approved, you are asked to provide project schedules with milestones and deadlines with very high-level requirements. Then some of these organizations say “let’s run these projects using agile methodologies”. What does that really mean?
What does that really mean if you have already broken down the project into a list of tasks and you estimated it all?
Can the agile team take these requirements and start assigning points to user stories and deciding how much to handle in a given week? In the meantime based on estimates, you already know how much needs to be handled in order to even have a chance to deliver the project?
Is that really fooling the members of the team believing that they will set the velocity based on how much the team can handle and in the meantime the estimates have been already committed?
Let me explain how I approach this. Let me first step back to the point when the estimates are being provided. What works for for me is reading the requirements document and breaking down the project into a list of features and sub-features. Then if the requirements document is written in such a way that it lists the user stories, you can easily distribute these user stories into the appropriate sub-features. If the requirements document does not explicitly list the user stories, then I would put a product owner hat on and extrapolate the user stories out of the requirements document.
Now that I have all the user stories under each sub-feature, I can do some high-level estimating on each story and the unit for estimation is the number of days. It is not some virtual story points and it is not hours; it is the number of day and you will see why later in this article.
After estimating each user story under each sub-feature, you can add up the estimates and have the list of sub-features and numbers for each sub-feature.
Now that you have the list of sub-features and estimate for each sub-feature, it is all fun after this point. It is fun because I like using Trello website to pre-plan all the sprints and ultimately produce the deadline (production launch date), because that’s what business expects from us. NOTE: I don’t do sprint planning at the user story level; I do this exercise of sprint pre-planning at the sub-feature level in order to produce that deadline and to have a rough idea how each sub-feature needs to be worked on throughout the project.
What are the steps to be taken before playing the drag-and-drop game in Trello?
- Decide on the duration of the sprint (let’s say 4 weeks)
- Take the list of sub-features and estimates and break down each sub-feature into multiple sub-feature parts that are each 5 days worth of work. For example, if you have a sub-feature that has the estimate of 20 days, then you would break that sub-feature into Sub-Feature A part 1, Sub-Feature A part 2, Sub-Feature A part 3, and Sub-Feature part 4.
- Now you are ready plug this all into Trello backlog list and then the game of dragging and dropping starts :)
Here is how it could look like in the backlog list when you start:

Now that you have all the sub-feature parts in the backlog, it is time to gauge what the optimal number of resources is. Let’s do some simple math.
- 6 resources
- 4 week sprints (20 working days)
- if everybody is a robot, then the team should be able to chunk away 120 days (6x20) out of the estimates. Yeah right !!! With all the meetings and interactions between teammates, a reasonable number to achieve in each sprint would be 60–80 days worth of work. If each part of the given sub-feature is equivalent to 5 days worth of work from the estimates, then you should be able to drag and drop 10+ of those parts into a given user sprint.
You as the technical lead and technical project manager know best how each sub-feature is related to each other and you are deciding those things as you are loading each sprint with the list of sub-feature parts.
Here is how it may look after going through this exercise. It looks like the duration of the project would be around 14 weeks (3.5 months). If you know what the start date is, then you can easily calculate the production launch date. You also know when you need to start each sub-feature and when each sub-feature is supposed to be completed. That can help you point out some major milestones to your senior management team.
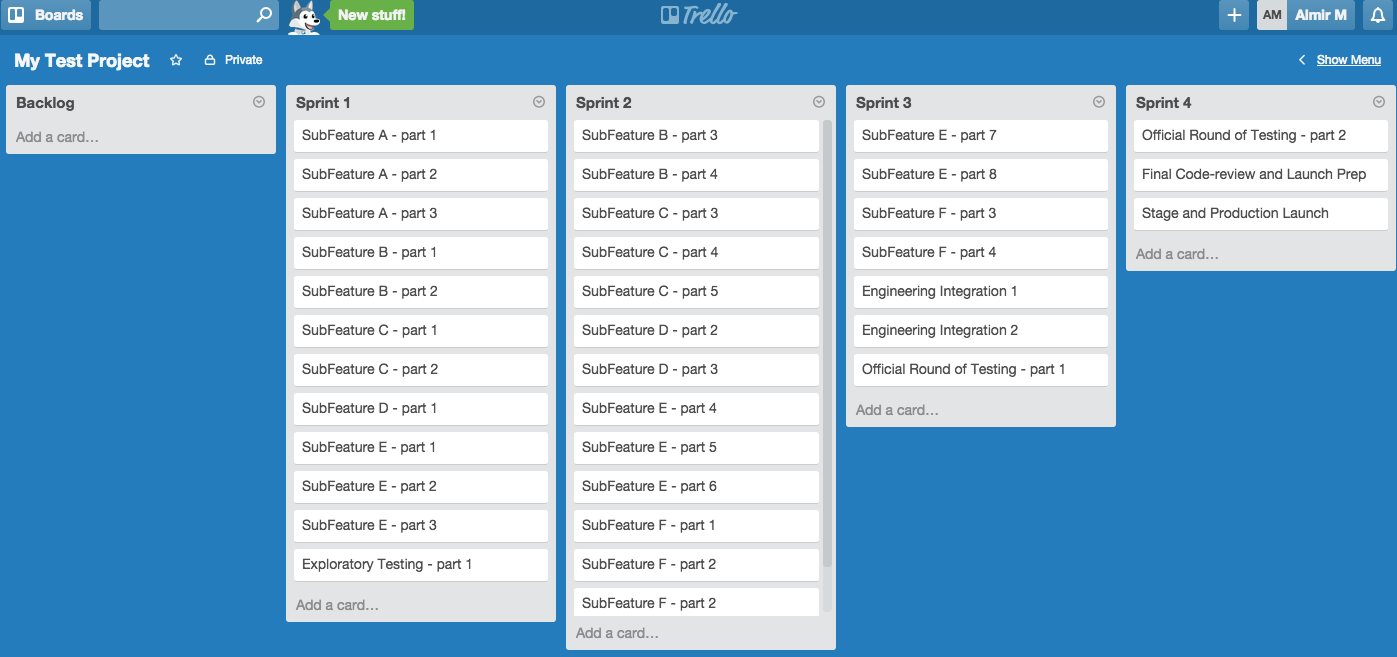
You are done. Provide your boss the duration of the project, major milestones and the production launch date that you can achieve based on these high-level estimates.
What’s next?
Well, now you need to share this with the team and help out the team do proper sprint planning at the user story level by using this sub-feature plan. I happened to use Trello just for the purposes of “sub-feature” planning, but when it comes to sprint planning at the user-story level, your team will need to use whatever tool your company approved.
Good luck and have fun.
Almir M (almirsCorner.com)
#Agile #AgileMethodology #ProjectManagement #ProjectPlanning #SoftwareEngineering #SoftwareDevelopment #Scrum #Planning #Trello #SAFe 
